Introducing SWEET: AI for Data Wrangling
For the third installment of our blog series, Let’s TAC™ About It, we’d like to introduce you to SWEET, a built-in function on VIA’s TAC™ platform. So, are you ready to TAC™ about it?
SWEET stands for Smart Wrangling Engine for Extraction and Transformation. Check out the video (or the transcription that follows) to learn how we use AI to wrangle data!
Below is a transcription of the “Introduction to SWEET: AI for Data Wrangling” video.
Analysts need to transfer data from a spreadsheet to a database, often known as data wrangling. The analyst usually identifies a rule or multiple rules (such as: column x is data, row 5 is a header and can be discarded, and so on). The analyst then writes code to execute that rule. This works well when rules are easily identifiable. In most cases, however, this is incredibly time consuming.
Data scientists spend more time wrangling and cleaning data than on analysis and AI. The problem with that is analytics insights are of the highest value, but get the least amount of resources. The big leap in AI is being able to process information without humans writing all the rules.
As an example, computer vision is used to identify a dog. Think of all the varieties of dogs and all the possible variations in context that those dogs could be in. There isn’t an army of people large enough to write rules to identify a random dog in a random photo.
And yet, AI can.
VIA’s approach to data wrangling is to use some of the exact same AI algorithms used in image recognition. This works across a much wider variety of contexts and spreadsheet or file formats. Let’s take a look at how SWEET works.
Here’s a spreadsheet. What SWEET is going to do is use a number of different machine learning algorithms to automate the process of getting the information into a database format.
The first model uses machine vision to map out the spreadsheet. Purple represents blank space, green is headings, yellow is actual data. Once that model has run, there’s a second algorithm that takes a look at the content.
The second algorithm skips over the purple. It looks at the green (which is the headers) to know which column to write where in the database. Finally, it would take a look at the yellow area to write the data to the database.
A third machine learning algorithm determines which column is derived from other parts of the sheet. For example, a total column is just the sum of the other columns and may not be necessary to write to the database. The third model separates these derived columns from the raw data.
In this example, the ACCOUNT column turns out to be the total of the other columns added up. It could be difficult for a human to understand immediately, but one of our models does this instantly.
SWEET’s approach works irrespective of the format. The model doesn’t have to be re-trained when it comes across spreadsheets that are new or in different formats.
So, what’s new and different here? AI algorithms have been evolving quickly. Many of the models that we implemented didn’t exist just a few years ago.
The other insight is that we broke the “convert this spreadsheet into a db” problem into multiple steps and have a different AI algorithm for each step.
Combined, SWEET, a built-in function in VIA’s TAC™ ingestion engine, helps make processes that used to take analysts days to do manually and makes them instantaneous.
Update: July 31, 2020
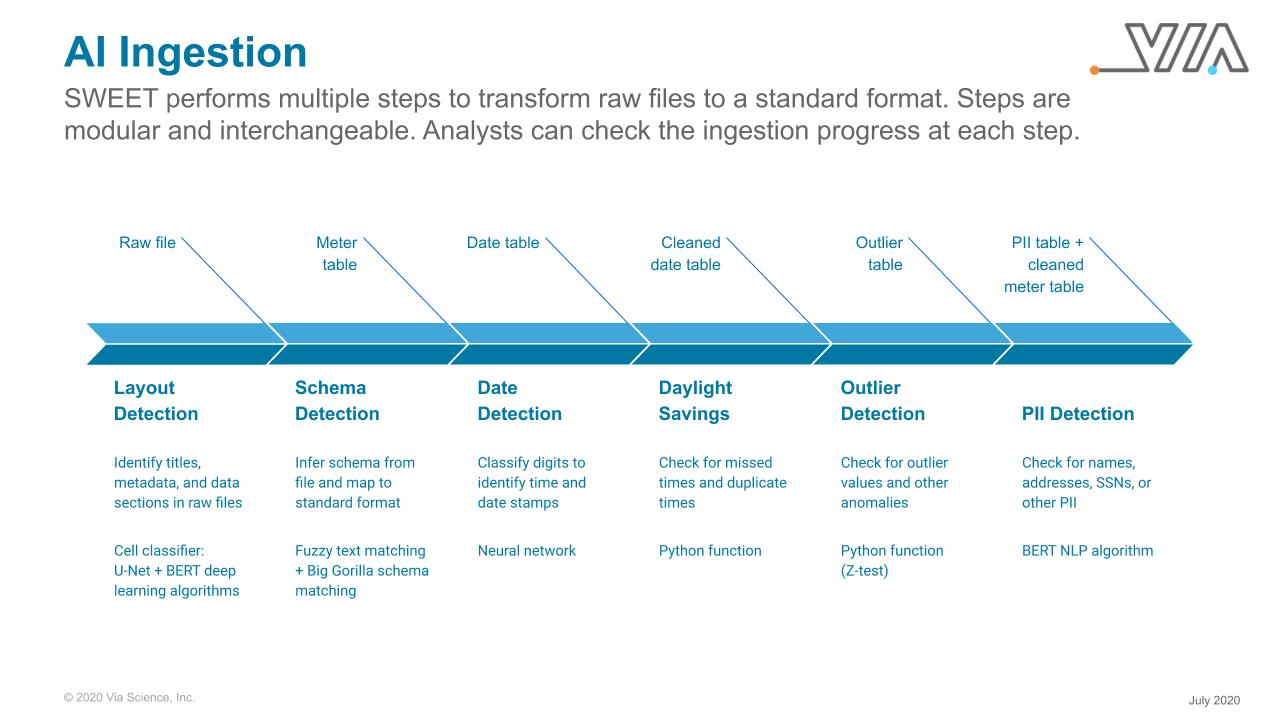
The image below shows the steps SWEET takes to transform raw files into a standard format.