
Let’s TAC™ About It: K-Anonymity
For the fifth installment of our blog series, we will cover TAC™’s k-anonymity functionality. So, are you ready to TAC™ about it?
Regulators are increasingly demanding that utilities release their data to third parties to support a wide array of clean energy initiatives. At the same time, regulators are also mandating increased information privacy and security requirements like with CCPA and GDPR.
The data about a consumer’s energy behavior can provide enormous insights for efficiency but, of course, they can also reveal private details like vacation habits, income levels, family size, etc.
How can utilities balance these two reasonable but competing requirements?
VIA has implemented a k-anonymity function to handle this use case. The essence of k-anonymity is to segment the data in such a way that similar consumers are in groups that are both big enough to hide an individual consumer’s behavior and small enough to be meaningful and useful for analysis and creating energy efficiency programs.
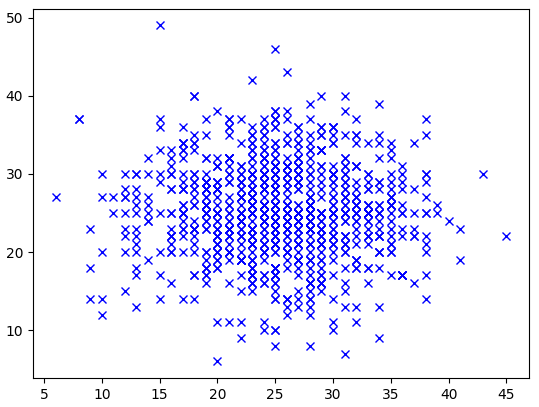
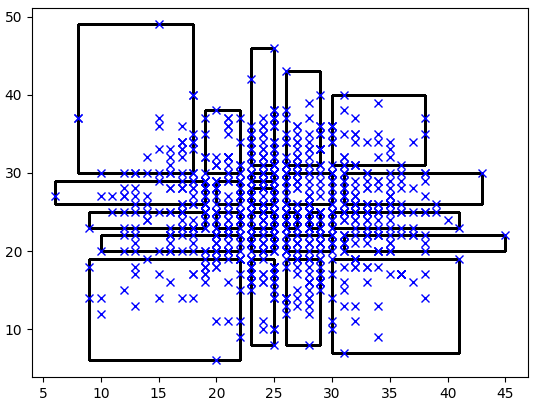
The above images show two normally distributed variables with 1,000 points. Each cross indicates one point. There can be several points at each location on top of each other. The second image shows the points grouped with at least 15 points within each group. The groups are smaller and more frequent in the middle because there are more points located in the middle due to the normal distributions.

K-anonymity algorithms are sometimes referred to as Mondrian algorithms due to the groupings resembling the paintings of Piet Mondrian.
Choosing an optimal grouping size is not just a challenge, it is actually an NP-hard mathematical problem. TAC™ now provides a simple function to allow utilities to implement k-anonymity groupings to meet both regulator constraints. When a utility chooses this function, any request of data must meet specific group size constraints. If not enough data exists to create a set of data that would maintain data privacy (e.g., only one consumer meets the specific request), then the utility does not provide the data. Similarly, if a data request is made where there is more than enough data to maintain an individual’s privacy, smaller groups of data will be created to allow for more targeted analysis.
Utilities facing regulatory constraints are excited by the opportunity to have an automated means of ensuring data privacy. As a sign of growing interest in the area, the utility non-profit EPRI (Electric Power Research Institute) is also facilitating a working group to test new solutions to the regulator dilemma.





