Transformer Tuesday: Anticipating EV Charging Challenges Facing Transformers
This is the sixth installment of our blog series, “Transformer Tuesday,” brought to you by VIA’s Will Chapman. In this series, we’ll address how leading utilities use VIA’s GDAC™ solution to manage their substation transformers with greater ease, insight, and cost effectiveness.
For 50 years, substation transformers were built to run during the day and taper down at night to cool. Now, picture your neighborhood lined with electric vehicles (EVs). Once your neighbors end their workdays and don’t need to use their vehicles anymore, they plug their EVs in to “juice up”.
While this is convenient for EV drivers, this significantly increased demand for evening voltage places additional wear-and-tear on the electricity grid during times when transformers are used to cooling down. In this scenario, transformers stay running and can overheat or experience a malfunction (not unlike a car if you think about it).
According to a 2021 McKinsey report, U.S. EV sales increased by nearly 200% between the second quarter of 2020 and the second quarter 2021. This number is expected to rise as a result of $7.5 billion EV infrastructure funding from the Bipartisan Infrastructure Investment and Jobs Act.
Growing fleets of EVs will clearly require utilities to expand their power capacity, and therefore, optimize or add transformers to handle more intense power requirements throughout the day and evening. This leads to critical questions like:
Which transformers should a utility repair, replace, or buy to add to their grids first?
Which units and future plans can wait?
How much will all of this cost?
Utility asset managers need to understand which transformers in their fleet are most at risk as EV penetration increases. VIA’s Global Data Asset Collaborative™ (GDAC™) can help.
Engaging with EV Stressors
Despite higher rates of EV adoption and challenges related to where and when EVs are being charged, utilities need to maintain the highest standards for electricity reliability and resiliency for their customers. GDAC™ identifies cases where transformers have unexpected declines in health condition, at an early age or in an area where previous transformer condition was consistent. These situations are good indicators to intervene sooner or review the assets in place.
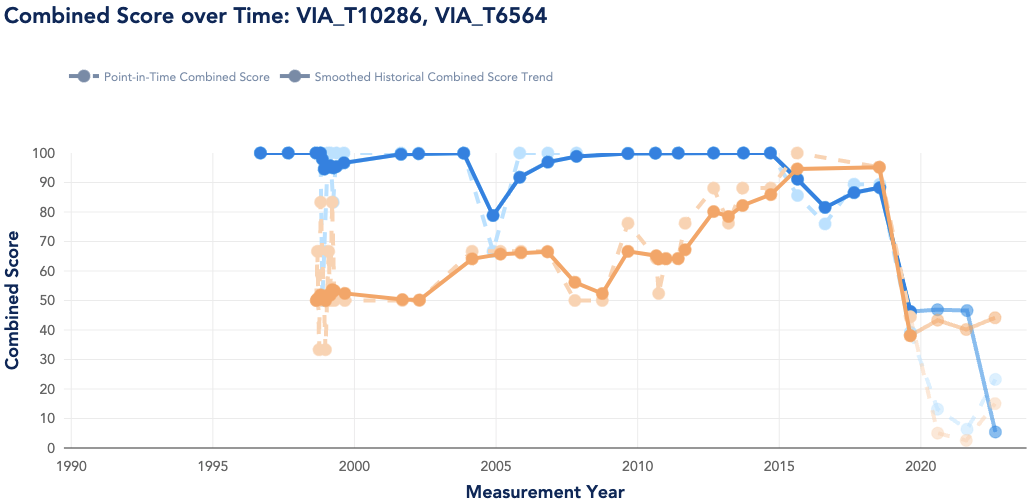
Utilities analyze historical and forecasted transformer condition changes (e.g., downgrades) in locations where EV adoption is high.
The GDAC™ portal conveniently flags high risk transformers for utilities so that they don’t have to parse through multiple databases, reports, and analyses, saving them invaluable time and effort. As a result, utilities can allocate resources to the transformers most in need, allowing them to work smarter.
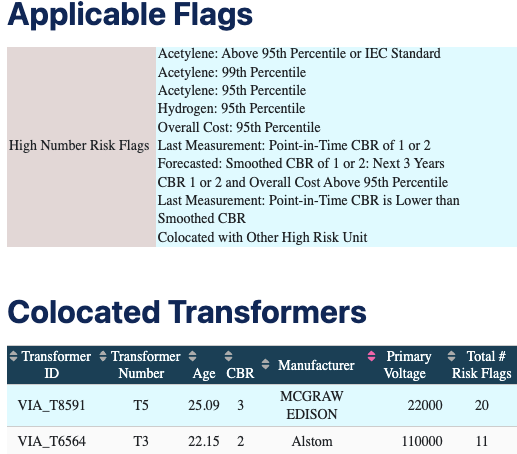
As shown in the diagram to the left, utilities easily identify transformers in need of maintenance or replacement due to EV-related stressors. Utilities also glean insights from transformers located at the same substation experiencing similar EV stressors.
GDAC™ analyses like these help utility personnel with or without analysis experience to identify which transformers to repair, replace, or buy; which units and future plans can wait; and how much it will cost to address EV-related stressors.
Want to go for a ride with GDAC™?
Reach out to me via LinkedIn or email sales@solvewithvia.com to learn more about the ways GDAC™ can help you be prepared for EV-related stressors on your transformer fleet.







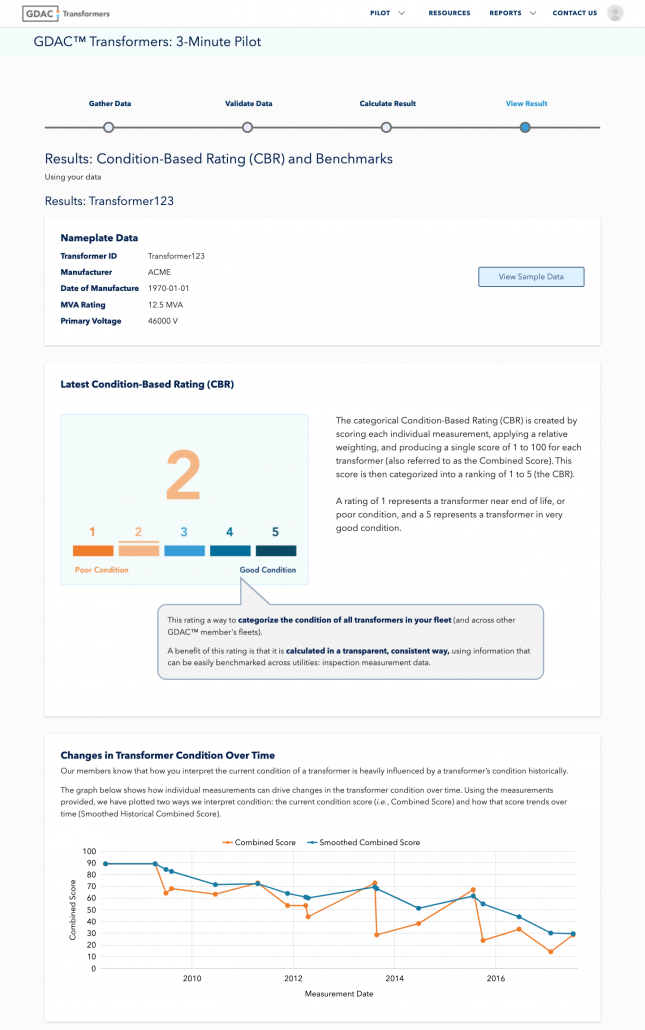 VIA’s 3-Minute Pilot provides valuable insights on the health of transformers in just 3 minutes.
VIA’s 3-Minute Pilot provides valuable insights on the health of transformers in just 3 minutes.